Vector Search
SurrealDB supports Full-Text Search and Vector Search. Full-Text search(FTS) involves indexing documents using the FTS index and breaking down the content of the document into smaller tokens with the help of analysers and tokenizers.
Vector Search in SurrealDB is introduced to support efficient and accurate searching of high-dimensional data. This guide will walk you through the essentials of working with vectors in SurrealDB, from storing vectors in embeddings to performing computations and optimizing searches with various indexing strategies.
What is Vector Search
Vector search is a search mechanism that goes beyond traditional keyword matching and text-based search methods to capture deeper characteristics and similarities between data.
It converts data such as text, images, or sounds into numerical vectors, called vector embeddings.
You can think of Vector embeddings as cells. Like how cells form the basic structural and biological unit of all known living organisms, vector embeddings serve as the basic units of data representation in vector search.
Vector search isn't new to the world of data science. Gerard Salton, known as the Father of Information Retrieval, introduced the Vector Space Model, cosine similarity, and TF-IDF for information retrieval around 1960.
If you’re interested in understanding Vector search in depth, checkout this academic paper on Vector Retrieval written by Sebastian Bruch.
Vector Search vs Full-Text Search
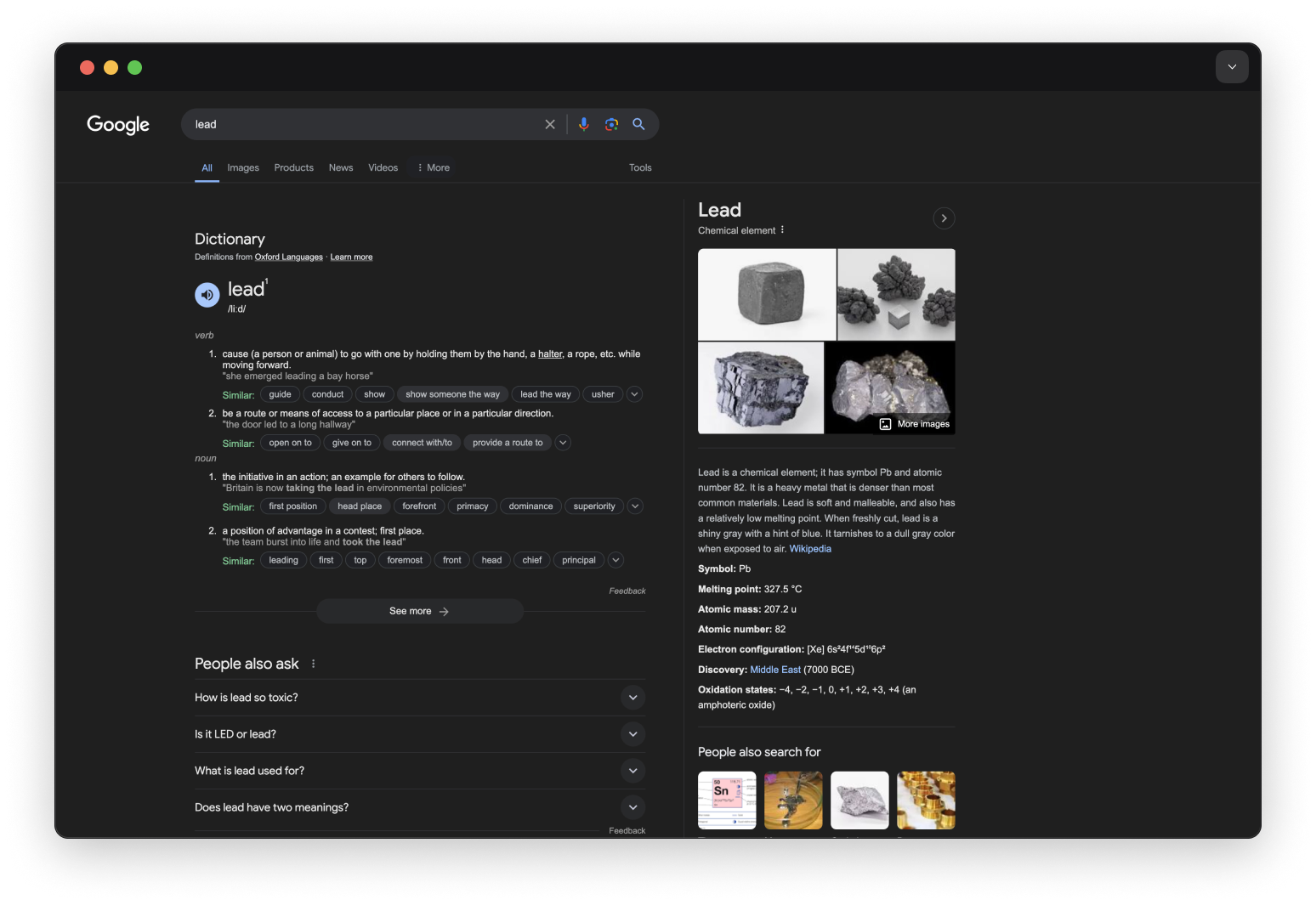
The image above is a Google search for the word “lead”. The search has pulled up different definitions of the word “lead”.
Lead can mean taking initiative, as well as the chemical element with the symbol Pb.
Now let’s add some context to the word. Consider a database of liquid samples which note down harmful chemicals that are found in them.
In the example below, we have a table called liquids with a sample field and a content field. Next, we can do a Full-Text index on the content field by first defining an analyzer called liquid_analyzer. We can then Define an index on the content field in the liquid table and set our custom analyzer (liquid_analyzer)to search through the index.
Then, using the select statement to retrieve all the samples containing the chemical lead will also bring up samples that mention the word lead.
If you read through the content of the tap water sample, you’ll notice that it does not contain any lead in it but it has the mention of the word lead under “The team lead by Dr. Rose…” which means that the team was guided by Dr. Rose.
The search pulled up both the records although the tap water sample had no lead in it. This example shows us that while Full-Text Search does a great job at matching query terms with indexed documents, it may not be the best solution for use cases where the query terms have deeper context and scope for ambiguity.
Vector Search in SurrealDB
The Vector Search feature of SurrealDB will help you do more and dig deeper into your data.
For example, still using the same liquids table, you can store the chemical composition of the liquid samples in a vector format.
-- Insert a sample & content field into a liquids table
INSERT INTO liquidsVector [
{sample:'Sea water', content: 'The sea water contains some amount of lead', embedding: [0.1, 0.2, 0.3, 0.4] },
{sample:'Tap water', content: 'The team lead by Dr. Rose found out that the tap water in was potable', embedding:[1.0, 0.1, 0.4, 0.3]},
{sample:'Sewage water', content: 'High amounts of a were found in Sewage water', embedding : [0.4, 0.3, 0.2, 0.1]}
];
Notice that we have added an embedding field to the table. This field will store the vector embeddings of the content field so we can perform vector searches on it.
You have the option of using 3 different approaches for performing Vector search.
As you want to perform a nearest neighbour search and not an exact search, you would typically use an index like HNSW or M-Tree.
In the example above you can see that the results are more accurate. The search pulled up only the Sea water sample which contains the harmful substance lead in it. This is the advantage of using Vector Search over Full-Text Search.
Another use-case for Vector Search is in the field of facial recognition. For example, if you wanted to search for an actor or actress who looked like you from an extensive dataset of movie artists, you would first use an ML model to convert the artist's images and details into vector embeddings and then use SurrealQL to find the artist with the most resemblance to your face vector embeddings. The more characteristics you decide to include in your vector embeddings, the higher the dimensionality of your vector will be, potentially improving the accuracy of the matches but also increasing the complexity of the vector search.
Now that you know how to handle a vector search query in SurrealDB, let's take a step back and understand some of its terms and concepts.
How to store vector embeddings
To store vectors in SurrealDB, you typically define a field within your data schema dedicated to holding the vector data. These vectors represent space data points and can be used for various applications, from recommendation systems to image recognition. Below is an example of how to create records with vector embeddings:
CREATE Document:1 CONTENT {
"items": [
{
"content": "apple",
"embedding": [0.00995, -0.02680, -0.01881, -0.08697]
}
]
};
The vector is represented as an array of floating-point numbers.
There are no strict rules or limitations regarding the length of the embeddings, and they can be as large as needed. Just keep in mind that larger embeddings lead to more data to process and that can affect performance and query times based on your physical hardware.
Computation on Vectors: "vector::" Package of Functions
SurrealDB provides Vector Functions for most of the major numerical computations done on vectors. They include functions for element-wise addition, division and even normalisation.
They also include similarity and distance functions, which help in understanding how similar or dissimilar two vectors are. Usually, the vector with the smallest distance or the largest cosine similarity value (closest to 1) is deemed the most similar to the item you are trying to search for.
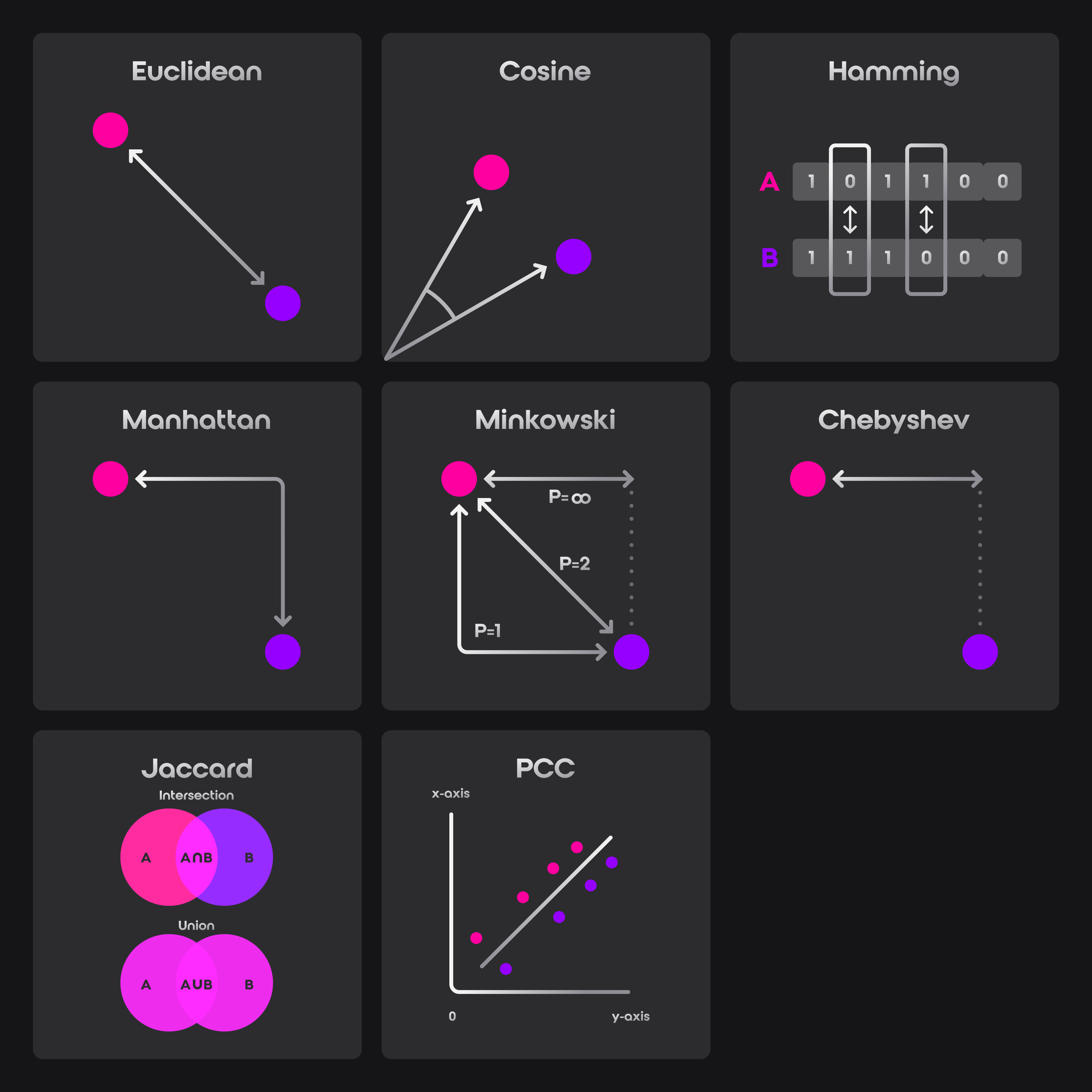
The choice of distance or similarity function depends on the nature of your data and the specific requirements of your application.
In the liquids examples, we assumed that the embeddings represented the harmfulness of lead (as a substance). We used the vector::similarity::cosine function because cosine similarity is typically preferred when absolute distances are less important, but proportions and direction matter more.
Vector Indexes
When it comes to search, you can always use brute force. In SurrealDB, you can use the Brute force approach to search through your vector embeddings and data.
Brute force search compares a query vector against all vectors in the dataset to find the closest match. As this is a brute-force approach, you do not create an index for this approach.
The brute force approach for finding the nearest neighbour is generally preferred in the following use cases:
-
Small Datasets / Limited Query vectors: For applications with small datasets, the overhead of building and maintaining an index might outweigh its benefits. In such cases, the brute force approach is optimal.
-
Guaranteed Accuracy: Since the brute force method compares the query vector against every vector in the dataset, it guarantees finding the exact nearest vectors based on the chosen distance metric (like Euclidean, Manhattan, etc.).
-
Benchmarking Models: The Brute force approach can be used as a reference, and help benchmark the performance of other approximate alternatives like HNSW
While brute force can give you exact results, it's computationally expensive for large datasets.
In most cases, you do not need a 100% exact match, and you can give it up for faster, high-dimensional searches to find the approximate nearest neighbour to a query vector.
This is where Vector indexes come in.
In SurrealDB, you can perform a vector search using the two primary indexes:
- M-Tree Index:
- The M-Tree index is a metric tree-based index suitable for similarity search in metric spaces.
- The M-Tree index can be configured with parameters such as the distance function to compare the vectors.
- Hierarchical Navigable Small World (HNSW) Index:
- HNSW (Hierarchical Navigable Small World) is a state-of-the-art algorithm for approximate nearest neighbour search in high-dimensional spaces. It offers a balance between search efficiency and accuracy.
- The HNSW index is a proximity graph-based index.
By design, HNSW currently operates as an "in-memory" structure. Introducing persistence to this feature, while beneficial for retaining index states, is an ongoing area of development. Our goal is to balance the speed of data ingestion with the advantages of persistence.
You can also use the REBUILD statement, which allows for the manual rebuilding of indexes as needed. This approach ensures that while we explore persistence options, we maintain the optimal performance that users expect from HNSW and MTree, providing flexibility and control over the indexing process.
Both indexes are designed to handle the challenges of searching in spaces where traditional indexing methods become inefficient. The choice between HNSW and M-Tree would depend on the application's specific requirements, such as the need for an exact versus approximate nearest neighbour search, the distance metric used, and the nature of the data.
Filtering through Vector Search
The vector::distance::knn() function from SurrealDB returns the distance computed between vectors by the KNN operator. This operator can be used to avoid recomputation of the distance in every select query.
Consider a scenario where you’re searching for actors who look like you but they should have won an Oscar. You set a flag, which is true for actors who’ve won the golden trophy.
Let’s create a dataset of actors and define an HNSW index on the embeddings field.
Note: You need to be running SurrealDB version 2.0.0 or higher to use the vector::distance::knn() function.
-- Create a dataset of actors with embeddings and flags
CREATE actor:1 SET name = 'Actor 1', embedding = [0.1, 0.2, 0.3, 0.4], flag =true;
CREATE actor:2 SET name = 'Actor 2', embedding = [0.2, 0.1, 0.4, 0.3]; flag =false;
CREATE actor:3 SET name = 'Actor 3', embedding = [0.4, 0.3, 0.2, 0.1]; flag =true;
CREATE actor:4 SET name = 'Actor 4', embedding = [0.3, 0.4, 0.1, 0.2]; flag =true;
-- Define an embbedding to represent a face
LET $person_embedding = [0.15, 0.25, 0.35, 0.45];
-- Define an HNSW index on the actor table
DEFINE INDEX hnsw_pts ON actor FIELDS embedding HNSW DIMENSION 4;
-- Select actors who look like you and have won an Oscar
SELECT id, flag, vector::distance::knn() AS distance FROM actor WHERE flag = true AND embedding <|2,40|> $person_embedding ORDER BY distance;
[
[
{
distance: 0.09999999999999998f,
flag: true,
id: actor:1
},
{
distance: 0.412310562561766f,
flag: true,
id: actor:4
}
]
];
actor:1 and actor:2 have the closest resemblance with your query vector and also have won an Oscar.
Conclusion
Vector Search does not need to be complicated and overwhelming. Once you have your embeddings available, you can try out different vector functions in combination with your query vector to see what works best for your use case. As discussed in the reference guide, you have 3 options to perform Vector Search in SurrealDB. Based on the complexity of your data and accuracy expectations, you can choose between them. You can design your select statements to query your search results along with filters and conditions. In order to avoid recalculation of the KNN distance for every single query, you also have the vector::distance::knn().
Due to GenAI, most applications today deal with intricate data with layered meanings and characteristics. Vector search plays a big role in analyzing such data to find what you’re looking for or to make informed decisions.
You can start using Vector Search in SurrealDB by installing SurrealDB on your machines or by using Surrealist. And if you’re looking for a quick video explaining Vector Search, check out our YouTube channel.